const task = tasks[idx]; task(data[idx], (err) => { if (err) return callback(err); iterate(idx + 1); }); }; iterate(0); // Callback이 재귀적으로 수행돼, N 만큼 수행된다.
이 방식의 한계:
실행될 작업의 숫자를 알아야 한다.
3. JS 경쟁 조건 해결하기
Javascript는 단일 스레드로 실행된다.
리소스 동기화는 필요 없지만, 비동기 API 타이밍 문제는 아직 남아있다.
Javascript 역시 호출 시점과 I/O 수행 시점 차이로 중복 작업 등의 예기치 않은 동작을 할 수 있다.
상호 배제로 해결 가능하다.
1 2 3 4 5 6 7 8 9 10
// 실행 중인 job을 등록한다. 공유 리소스 동기화는 필요 없다. const jobs = newMap(); const fn = (id, data, callback) => { // 이 코드로 타이밍 문제를 해결할 수 있다. if (jobs.has(id)) return process.nextTick(callback);
jobs.set(id, true); // 정상 분기. };
4. 동시에 수행되는 작업 개수 제한 하기
한 번에 너무 많은 파일을 열려고 하는 등의 경우 리소스 부족으로 뻗어버릴 수 있다. 동시에 실행하는 작업의 수를 제한해 이를 상황을 방지하는 아이디어를 소개한다.
const tasks = [ /* ... */ ]; const limit = 2; // 동시 실행 제한 개수 let running = 0, completed = 0, idx = 0;
const next = () => { // 여유 작업 개수만큼 반복 while (running < limit && idx < tasks.length) { const task = tasks[idx++]; task(() => { // 새 작업을 할 수 없음 if (completed === tasks.length) return finish(); completed++; running--; next(); // 새 작업을 할 여유가 있음 }); running++; } };
// Queue로 구현하는 방식 // 로직은 같은데 Queue를 사용하는 것만 다르다. classTaskQueue{ constructor(limit) { this.limit = limit; this.running = 0; this.queue = []; }
// task :: callback => void; (must call callback) // task를 tasks에서 가져오는 게 아니라, Queue에 넣은 것이 나온다. // => 새 작업을 큐에 동적으로 추가할 수 있다. pushTask(task) { this.queue.push(task); this.next(); }
Node.js는 Event Emitter라는 미리 구현된 객체를 코어 모듈(events)로 포함하고 있다. 이 객체는 emit, on, once, removeListener 로 구성된 총 4개의 메소드를 갖고 있다. 아래는 각 메소드의 사용 예시이다.
CodeSandBox가 Node.js를 Beta로 지원하고 있으므로 출력이 정상적이지 않을 수 있습니다. 왼쪽의 탭을 드래그해 코드를 확인해주세요.
아래는 File을 읽는 예제이다.
3. Event Emitter 에서의 예외 처리
Event Emitter에서도 비동기 이벤트의 경우, CPS와 마찬가지로 예외가 발생하는 경우 기존 스택을 잃기 때문에 (리액터 패턴 참고) try-catch로 무조건 예외를 처리하여야 한다. 이후 error 이벤트를 발생시켜 리스너들에게 전달함이 일반적이다.
4. Event Emitter 상속하기
아래와 같이 EventEmitter를 상속하여 인스턴스에 대해 .on을 붙이는 등의 작업을 할 수도 있다. 책에서는 일반적인 패턴이라고 하지만, emit 메소드까지 의도치 않게 Public API가 되기 때문에 추천하는 방식은 아니다. 위임으로 on, once, removeListener를 따로 API로 내보내는 게 맞다고 생각한다.
1 2 3 4 5 6
classFindPatternextendsEventEmitter{ //... }
const findPattern = new FindPattern(/hello \w+/g); findPattern.on(/* ... */);
5. 동기, 비동기 이벤트 별 리스너 등록 시점
이벤트를 동기적으로 발생시키려면, 리스너 등록을 이벤트 발생 이전 시점에 완료하여야 한다.
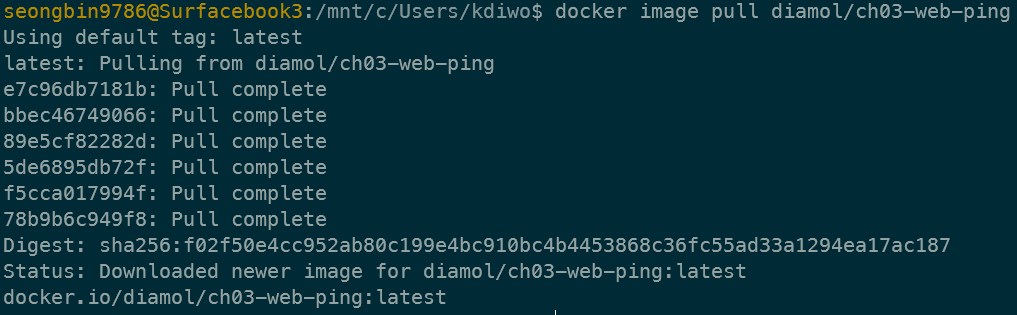
(Mandatory) .은 Dockerfile 및 COPY 등에서 Host의 기준 디렉토리로 사용된다.
(Mandatory) --tag는 이미지의 이름을 지정한다.
주의: 파일을 Windows -> Linux로 복사하는 경우, 권한이 rwxrwx로 지정되는데, 이는 서로 권한 정보가 호환되지 않기 때문이다.
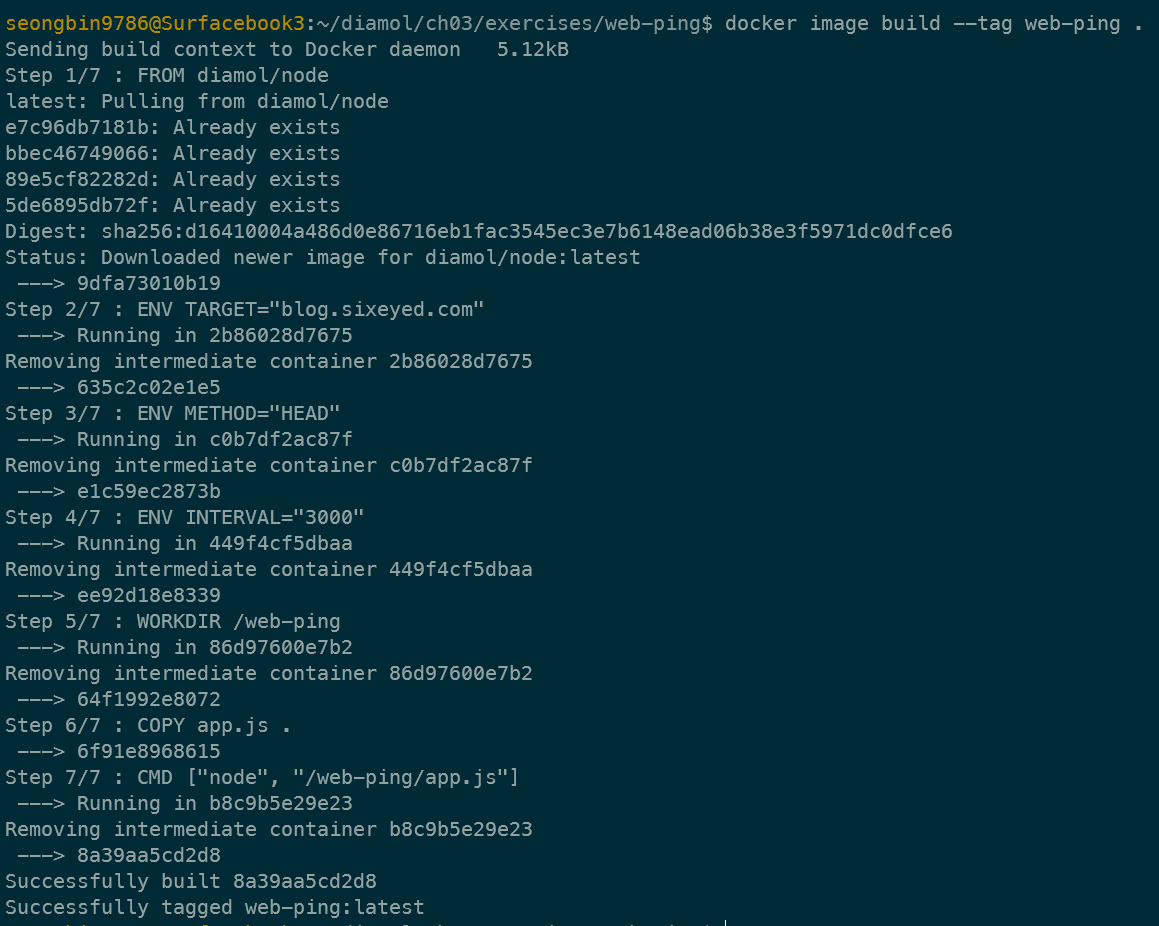
로컬에서 직접 빌드된 이미지는 도커 엔진에 캐시돼 보관된다.
새로운 버전을 빌드하려는 경우, --tag web-ping:v2와 같이 :으로 버전을 구분하여 명시하면 된다.
5. Image 실행(컨테이너로):
docker container run {image_name}으로 실행
6. Image Layer:
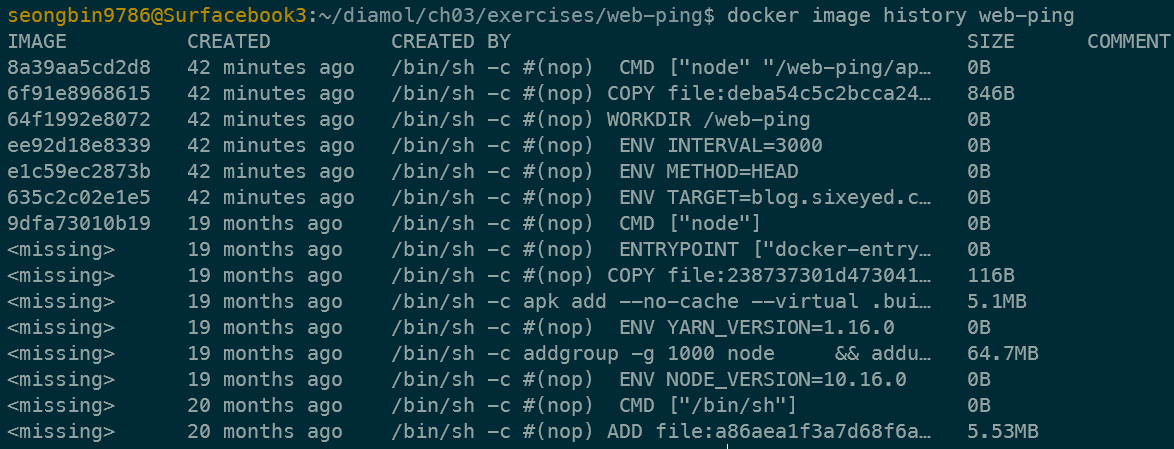
이미지에는 생성 과정에 대한 메타데이터도 포함된다. 이미지 생성 과정을 통해
docker image history web-ping
Docker Image는 Image Layer라는 더 작은 개념으로 구성되며, Dockerfile의 각 명령(CREATED BY) 마다 Layer가 생성된다.
이미지는 각 Layer의 논리적인 집합이다.
Layer는 도커 엔진에 물리적인 파일의 형태로 캐시되는 단위이다.
이미지 간에 Layer가 공유되므로 전체 용량 부하를 낮출 수 있다.
docker image ls로 논리적인 용량을 확인할 수 있지만, docker system df로 이미지가 차지하는 물리적인 용량을 확인할 수 있다.
이런 Image Layer 캐시를 활용하려면 조건이 필요한데: Layer 이전의 Layer 들의 내용과 순서가 바뀌지 않아야 한다.
이전 내용이 바뀌었는데, 이 명령(Layer)을 실행한 결과가 같음을 보장할 수 없다.
만약 내용을 바꾸는 경우, 이 Layer에 의존하고 있던 모든 이미지에 영향을 끼친다.
그러므로, 이전 Layer가 변경되는 경우, 이후 Layer는 캐시로 사용될 수 없게 되고, 새로 Layer를 생성하게 된다.
7. Layer 캐시 최적화 전략: Layer 캐시 활용을 통해 전체 용량과 이미지 빌드 시간을 줄일 수 있다.
이미지에서 변하지 않는 부분을 최대한 먼저 실행해 새로 빌드할 Layer 수를 줄인다.
캐시 사용 가능 여부는 Instruction의 내용과 Arguments(명령어 내용일 수도 있지만, COPY와 같은 경우 파일의 내용까지.)로 Hash 값을 만들고 비교하여 결정한다.
Hash가 일치하는 경우 빌드하지 않고 도커 엔진에 캐시된 Layer를 사용한다. 일치하지 않는 경우, 해당 Layer부터 최종 Layer까지 새로 빌드한다. (뒷 Layer의 해시가 같아도, 재사용할 수 없다.)
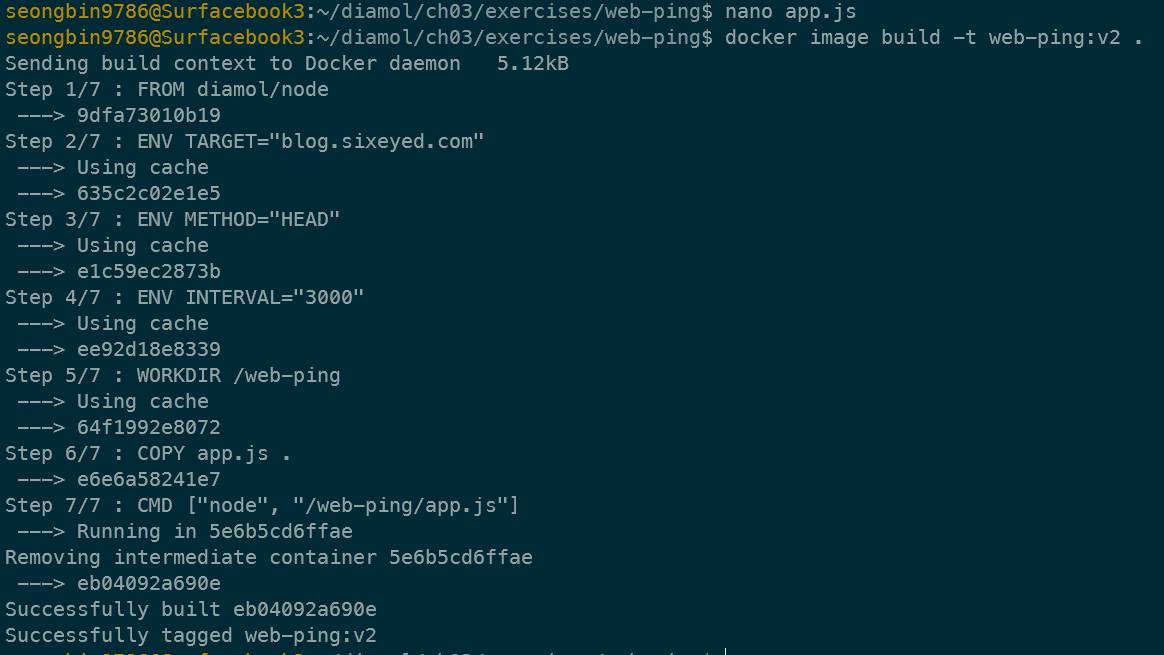
app.js 파일을 수정한 후 (nano app.js) 빌드한 모습이다. COPY app.js를 수행하는 step 6가 다시 Layer를 만듦을 확인할 수 있고, 이후 Layer인 step 7은 바뀐 내용이 없지만 앞 Layer가 바뀌어서 다시 만들어짐을 확인할 수 있다.
8. Layer 캐시 최적화 예시:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
FROM diamol/node
# 시작 시 실행될 명령어를 지정하는 것이므로, 어디에 놓아도 상관 없다. # 캐시를 위해 앞에 놓는다. CMD ["node", "/web-ping/app.js"]
# 환경 변수 3개를 한 번에 등록해 Layer 개수를 줄였다. # 개수를 줄인 것과 캐시 최적화는 큰 연관은 없지만... ENV TARGET="blog.sixeyed.com" \ METHOD="HEAD" \ INTERVAL="3000"
WORKDIR /web-ping
COPY app.js .
이제 docker image build -t web-ping:v3를 실행해보자. 환경 변수 개수가 줄어들어 7단계에서 5단계로 줄었음을 확인할 수 있다.
이제부턴 app.js를 수정해도 마지막 Layer만 바뀐다.
2. 실습
1. 목표:
diamol/ch03-lab 폴더의 이미지에서 /diamol/ch03.txt 파일을 수정하고 새 Image를 생성하라. 이 때 Dockerfile을 수정해서는 안 된다.
2. 힌트:
-it으로 컨테이너에 키보드 I/O 가능
컨테이너 파일 시스템이 Exit 상태에도 제거되지 않음을 활용
docker container --help로 모르는 명령어에 대해 공부할 것
3. 처음 생각한 접근 방법:
Container에서 일단 파일을 수정한다.
컨테이너로 이미지를 생성해낸다. 명령어를 찾아보자.
4. 실제 수행 과정:
1. 일단 이미지를 빌드함
cd ../../lab (빌드를 위해 lab 폴더로 이동)
docker build image -t ch03-lab . (빌드 성공)
2. 이제 컨테이너를 실행해야 함
docker container run ch03-lab (실패)
docker container ls (없었음)
cat Dockerfile (CMD 등 명령어 실행이 없고, COPY 뿐이었음)
3. 컨테이너에서 수행할 명령어로 주어 실행해야 함
docker container run ch03-lab /bin/bash (실패)
docker container run ch03-lab /bin/sh (이미지에 bash가 없었음..)
# 구독할 이벤트 on: push: branches: [master] pull_request: branches: [master]
# jobs 단위로 개별 서버(정확히는 Docker 컨테이너 단위라고 한다.)에서 작업이 수행된다. # 각 작업은 병렬로 실행 된다고 하는데, needs: build와 같이 표시해서 기다릴 수도 있다. jobs: build: # Ubuntu, Windows, MacOS를 지원한다. runs-on:ubuntu-latest
# 영상에서도 소개됐는데, 변수 개념으로 생각하면 된다. # node-version 과 같이 배열로 돼있으면, 해당 원소를 순회하면서 작업이 반복해서 실행된다. # matrix 때문인지 배열만 되는 것 같다. (TODO) # 응용해서 runs-on에 여러 OS에서 돌릴 수도 있다. strategy: matrix: node-version: [14.x] # 템플릿 기본값: [10.x, 12.x, 14.x]
# uses 개념은 다른 사람이 작성한 내용을 실행하는 개념이다. # actions/checkout: GitHub의 마지막 커밋으로 Checkout 한다. # actions/setup-node: Node.js를 설치한다. # run 개념은 명령어를 실행한다. 셸 스크립트와 동일하다. steps: -uses:actions/checkout@v2 -name:UseNode.js${{matrix.node-version}} uses:actions/setup-node@v1 with: node-version:${{matrix.node-version}} # npm ci는 npm install과 같은 기능을 수행한다. 자세한 내용은 아래 링크 참조. -run:npmci # --if-present 옵션은 npm 스크립트가 존재할 때만 실행시키라는 의미이다. # 만약 build 스크립트가 없는 경우, 오류 없이 지나간다. -run:npmrunbuild--if-present -run:npmtest
Jest는 글로벌로 API를 expose하기 때문에 ESLint error가 나지 않으려면 플러그인을 설치해줘야 한다.
npm i --save-dev eslint-plugin-jest 로 ESLint-Plugin-Jest를 설치한다.
eslintrc.yml 파일에 아래의 내용을 추가한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
//... env: //... jest:true# Jest 글로벌 plugins: -jest# Jest 테스트를 위해 플러그인이 필요하다. rules: //... # Jest Eslint 옵션은 0,1,2 (off, warn, error) 만 옵션으로 사용 가능하다. jest/no-disabled-tests: -warn jest/no-focused-tests: -error jest/no-identical-title: -error jest/prefer-to-have-length: -warn jest/valid-expect: -error
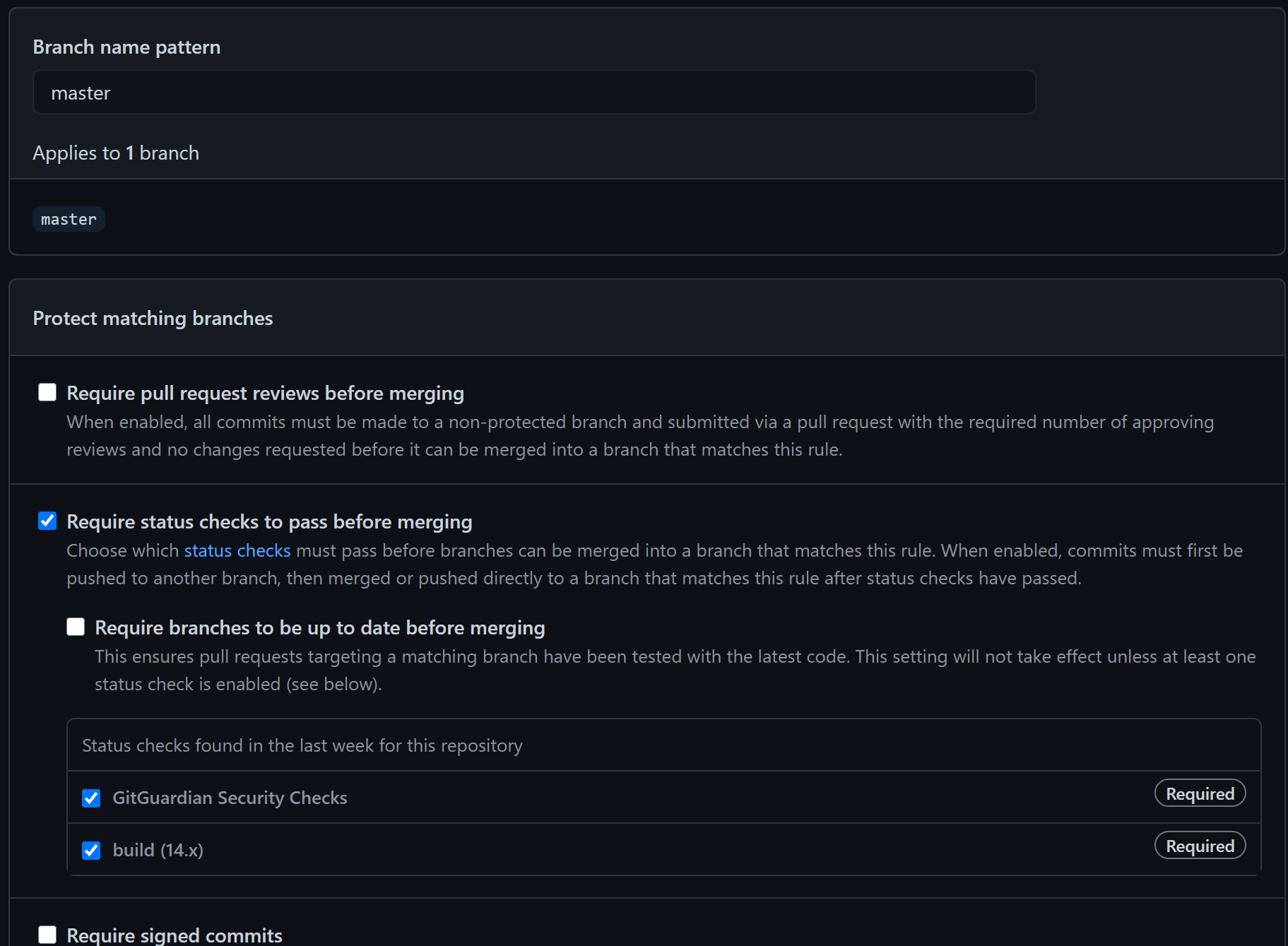
GitHub에서 Branch Protection Rule이라는 기능을 제공한다. 레포지토리 > Settings 탭 > Branches 탭 > Branch protection rules 탭 > Add Rule 버튼 클릭 후 아래와 같이 설정하였다.
4. 끝!
ci.yml 파일을 Push 하자.
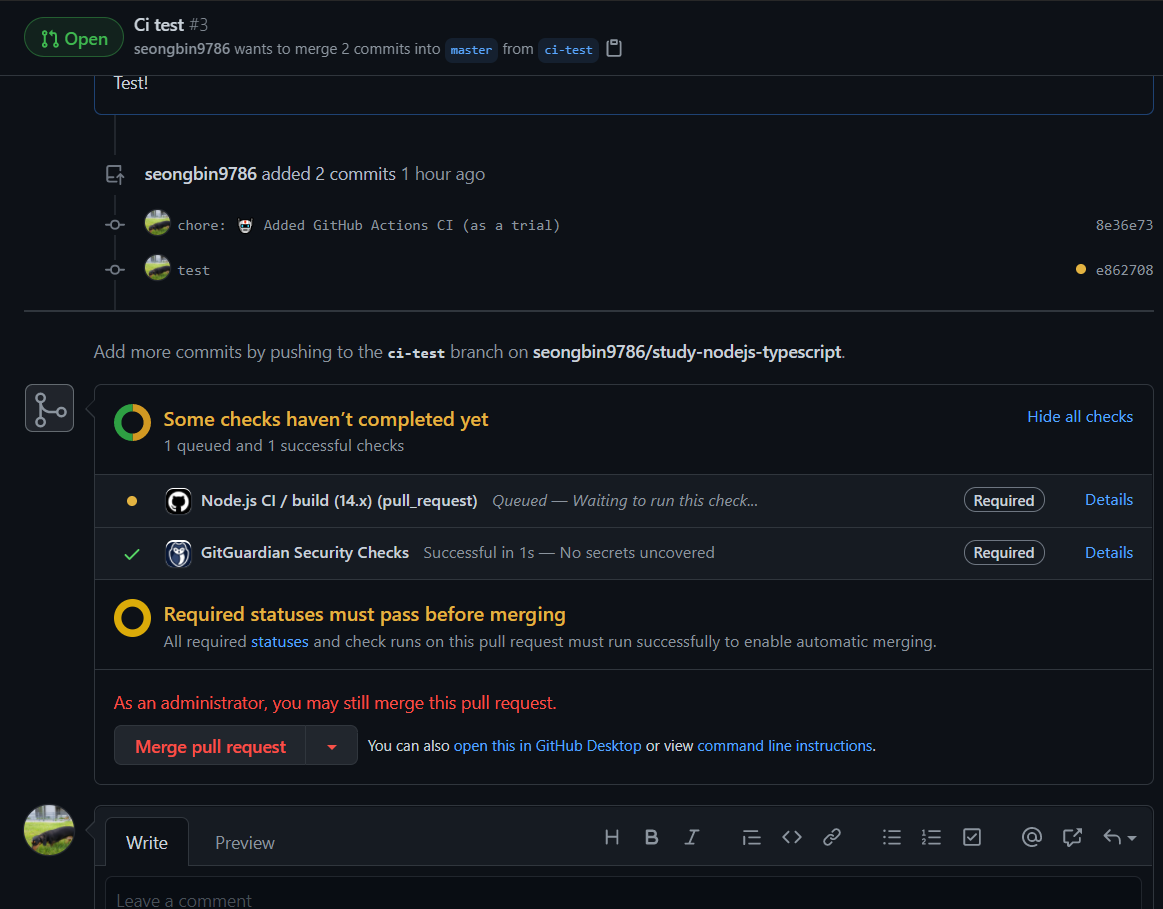
Master에 Push하거나 Pull Request를 올리자
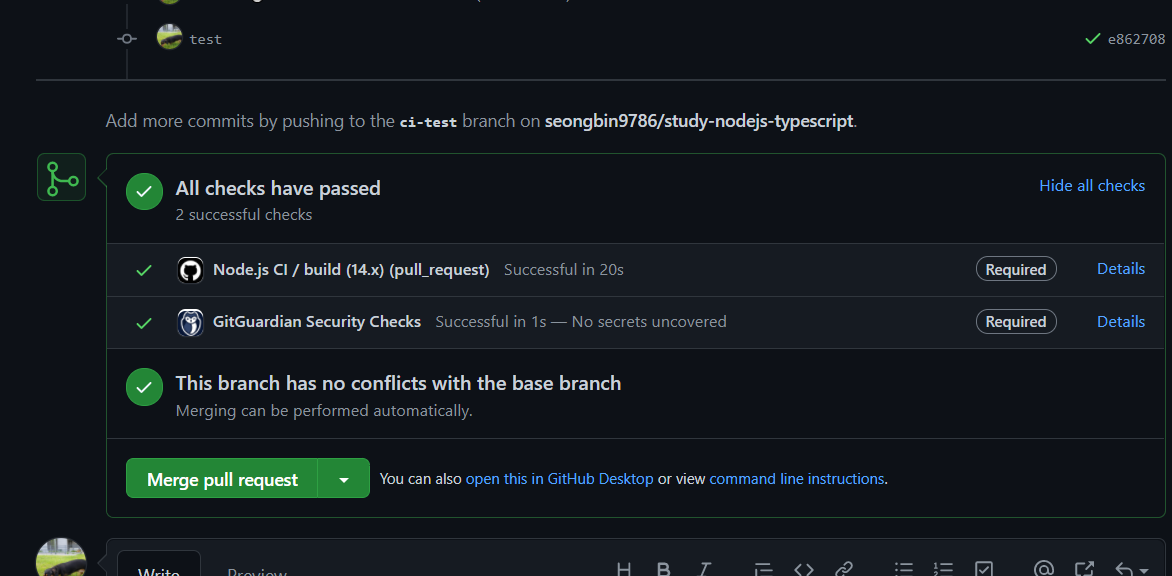
CI가 동작함을 확인하자.
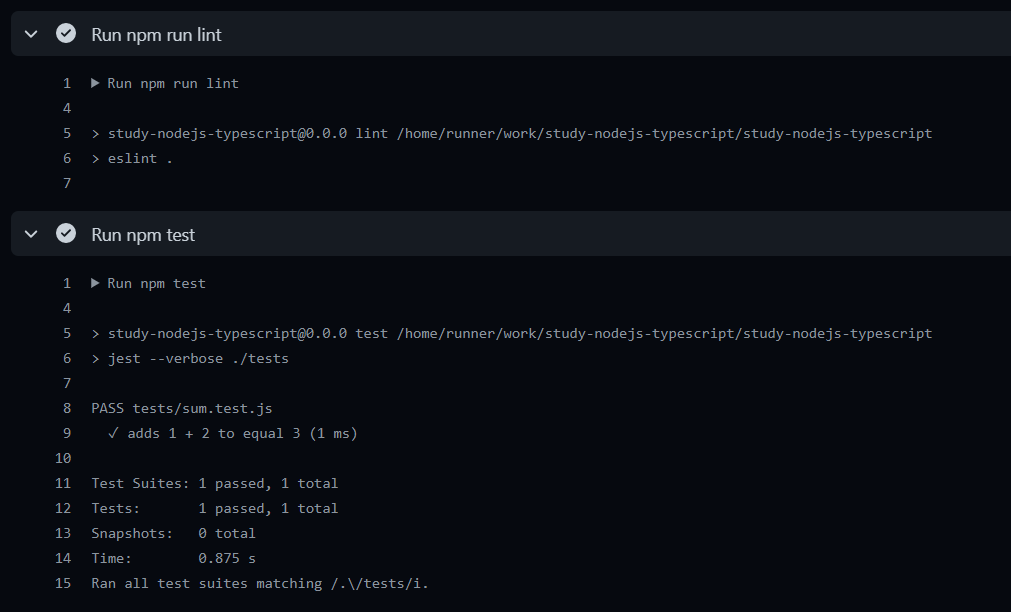
글쓴이는 아래처럼 잘 동작함을 확인했다.
코드 베이스가 작고, 테스트가 사실상 전무하지만, 그래도 Node 설치부터 실행까지 20초밖에 걸리지 않는다는 점은 신기하고 인상적이다. Public 레포로 작업하면 좋은 성능의 CI를 무료로 사용할 수 있어 좋은 것 같다.
TODO
CD 과정도 구축하기. Docker 레지스트리 배포가 일반적인 듯하다. (쿠버네티스가 사용되는듯)
Jobs에서 build 하나만으로 괜찮은 것 같긴 한데, 나누는 case는 뭐가 있을지 확인해보기
npm run build 명령어로 무엇을 실행할지 고민해보기. Node.js로 프로덕션 배포를 해 본 적이 없어서 뭐가 필요한지 아직 파악하지 못 했다.
GitHub Actions에 대해 이론적으로 더 공부해보고, 할 수 있는 것들 더 많이 배우기
Git Hooks라는 개념도 있다고 한다. 로컬 수준에서도 프로세스를 자동화할 수 있는 것 같은데, 한 번 알아봐야겠다.
기타 내용 정리
Why is it free?
public은 무료, private은 사용량 만큼 낸다고 한다.
왜 무료일지 확인해봤는데, 출처에 따르면 Open Source 프로젝트 지원이라는 명목이다.
We want every open source project to be productive and use best practices, so Actions is free for the 40 million developers on GitHub to use with public repositories. For private repositories, Actions offers simple, pay-as-you-go pricing. (…)
Supported OS
위에서 언급했듯, Ubuntu, Windows, MacOS 이다. Docker 컨테이너로 작동한다고 하며, 매 번 Fresh한 Docker Container가 제공된다고 한다.
계기가 된 Video
참고한 유튜브 비디오. 간단하게 Github Actions이 뭔지 영상을 보기만 해도 파악이 가능하다.
이 박스에는 기기명, IP 주소, 스토리지가 딸린, Docker에서 만들어낸 논리적인 가상 컴퓨터가 있다.
애플리케이션은 이 컴퓨터에서 실행된다.
박스 안의 애플리케이션은 박스 밖을 볼 수 없다.
이 박스는 여러 개가 동시에 실행될 수도 있다.
박스는 같은 실제 컴퓨터를 공유하면서 격리된 환경을 갖는다.
일관된 작업 방식: 아무리 애플리케이션이 복잡하더라도 Docker Image 단위로 Share, Run 만 하면 된다. 몇 개의, 어떤 컴포넌트, 설정 파일, 라이브러리를 사용하는지는 중요하지 않다.
Portability: Docker가 있는 컴퓨터에선 명령어 하나로 곧바로 설치가 가능하다.
효율적인 자원 활용: 도커는 VM이 그렇듯, 여러 애플리케이션을 동시에 실행하는 것으로 컴퓨터 자원을 최대한 활용할 수 있다. 다만 VM보다 나은 점을 아래 표로 정리했다.
사용 자원
Docker
VM
Guest OS 사용 여부
No (커널 공유)
Yes
가상화 리소스 비용
매우 낮음 (커널 공유)
독립적인 OS 수준
Gust OS Update 다운로드
Base Image 교체
수동 설치
아주 작은 앱 띄우기
Yes
No
인수인계/배포 비용
A Dockerfile
hours of installation
책에서는 Guest OS License 비용 문제에서도 차이가 난다고 언급했지만, Docker Image 형태로 쓴다고 해서 License 비용이 낮아지거나 사라지지는 않을 것 같다. 반대로 대수가 늘어나기 때문에 Open Source 기반으로 사용하지 않을까 생각이 든다.
docker container rm –force $(docker container ls –all – quiet)
모든 컨테이너를 강제 제거
종료된 컨테이너는 제거된 것이 아니어서 계속 용량을 차지하며, 아래 작업이 가능하다.
그대로 다시 실행
컨테이너 내의 App이 생성한 로그를 확인
파일을 Host에서 or Host로 복사
컨테이너의 네트워크:
기본적으로, 각 컨테이너는 Host 네트워크에 대해 격리된다. 컨테이너는 Host 내의 가상 사설망으로 구성된다.
Docker는 Host의 네트워크 트래픽을 가로채 컨테이너로 보낼 수 있다.
Docker가 컨테이너를 실행하는 방법:
Docker Engine은 Docker Backend이다. Docker API(HTTP 기반의 REST API)를 제공한다. 이미지 재사용에 관한 기능은 직접 하고, 컨테이너는 containerd에 기반해 관리한다고 한다. containerd는 CNCF에 의해 관리되는 오픈소스 프로젝트이다.
Docker CLI: Docker의 Frontend이다. Docker Engine과 소통하는 방법을 제공한다.
기타 정보:
Docker는 가장 인기가 많은 컨테이너 플랫폼이지만, 다른 기술도 있으며 컨테이너 기술로 인해 플랫폼에 락인될 걱정은 하지 않아도 된다.
Docker는 이미지를 사용해 컨테이너를 실행한다. 이 때 이미지가 로컬에 있어야 한다. docker container run을 할 때에 없으면 docker pull을 받게 된다. 한 번 다운로드한 이미지는 재사용한다.
도커 컨테이너 Id는 컨테이너의 hostname이 된다.
컨테이너를 선택할 때, 이름 앞 몇글자만 입력해도 된다. 예: f1695...일 때, docker container top f1만 해도 된다.
컨테이너는 독립된 파일 시스템을 가지며, 컨테이너 내의 웹 서버 또한 컨테이너의 파일 시스템의 파일을 제공한다.
docker container 명령어를 통해 컨테이너에서 수행할 수 있는 명령어 목록을 볼 수 있다.
docker {command} --help를 통해 해당 명령어의 상세 설명을 확인할 수 있다.
diamol/ch02-hello-diamol-web 이미지는 /usr/local/apache2/htdocs 폴더 내의 파일을 정적으로 제공한다. (윈도우의 경우, C:\user\local\apache2\htdocs 폴더.)
내 풀이
풀이 과정을 서술함.
1. 제공된 컨테이너 트러블 슈팅: 일단 ch02-hello-diamol-web 의 기본 포트인 8088은 접속할 수가 없었다. 그래서 DockerHub 가서 Apache 이미지를 받아서 실행해봤다. 8080 포트로 잘 되더라. 이 때 명령어가 $ docker run -dit --name my-apache-app -p 8080:80 -v "$PWD":/usr/local/apache2/htdocs/ httpd:2.4 였는데, 배운 점:
-dit: --detach --interactive의 약자인데, -dit가 필요한 이유를 보면, bash 스크립트가 엔트리 포인트인 경우 -d만 하면 정지된 상태에서 아무것도 못한다고 한다. -it를 줘서 셸이 있어야 스크립트가 실행된다고 한다.
-p: --publish의 약자이다.
-v: 아직 안 배웠지만, 볼륨 개념일 것으로 추정된다.
도커 자체의 네트워크 문제가 아님을 알고, 80으로 하니까 잘 됐는데, 이유는 모르겠다.
2. 컨테이너 셸 접속: 일단 docker container exec -it --tty {id} /bin/bash 로 접속할 순 있었다. (나오는건 exit 치면 된다.)
모듈 시스템은 프로그램의 구성 요소들 간의 역할을 분리하고, 의존 관계와 구현 상세를 격리하는데 필수적이다. 모듈 시스템의 문법으로 보면, 소스 파일간의 import, export를 하는 것인데, 개념 상 Java의 접근 제한자 - private, protected, public - 도 모듈의 역할 중 일부를 수행 한다고 할 수 있다.
Javascript 모듈 시스템으로는 대표적으로 ESM, CommonJs 라는 두 개의 기술이 있는데, 현재의 Node.js는 ESM, CommonJs를 모두 지원한다.
// 이 객체를 반환하므로, 외부에선 privateFoo, Bar에 접근할 수 없다. return { increase, decrease }; })(); // 즉시 실행하여, { increase, decrease } 객체가 반환된다.
3. CommonJs의 require 방식에 대해
CommonJs는 const moduleA = require('./moduleA');와 같이 모듈을 로딩하는 문법을 제공한다. require는 동기로 작동하고, 한 번 로딩한 모듈은 캐시된다. 내보낼 때에는 각 모듈별로 제공되는 exports 객체에 필드를 할당하는 방식으로 진행한다.
Node.js 환경에서 순환 참조를 하는 경우 한 모듈이 먼저 로딩되기 때문에, 동기로 로딩하는 경우, 한 쪽에서는 null, 한 쪽에서는 정상 로딩이 될 수 밖에 없다. 아니면 명확한 순서를 지정해준다면 해결할 수도 있겠지만(A[A.B = null]->B[B.A = A]->[A.B = B]), 순서를 명시하는 API가 따로 있는지 잘 모르겠다.
한 쪽에서 느린 초기화를 진행한다. (Lazy-Init) - 순서 정하기와 사실상 동일함.
순환 참조 관계에 있는 두 객체를 제 3의 객체에 의존하도록 한다. 관련 스택 오버 플로우 - 이 부분은 잘 이해하지 못 했다.
어떻게 export 해야 좋은 모듈일까?
1. Substack 패턴
모듈의 기능을 객체가 아닌 함수 단위로 노출한다. 진입점이자 주가 되는 함수를 module.exports로 내보내는데, 따라서 const logger = require('./logger')와 같이 바로 사용할 수 있는 함수가 된다. 또한, logger.verbose(msg); 와 같이 서브 함수들도 내보내, 사용하는 입장에서 기능의 중요도를 쉽게 파악할 수 있게 한다.
이 글은 CPS 패턴과 CPS가 Node.js에서 어떻게 사용되고, 어떤 점을 주의해야 하는지 다룬다.
1. CPS 패턴
Node.js는 1장에서 살펴봤듯 비동기 특성을 가지며, 따라서 Node.js 앱은 대부분의 일을 비동기로 처리할 수 밖에 없다. 비동기를 처리하는 방법 중 CPS, Continous Passing Style을 소개한다.
CPS: 비동기 API를 사용할 때, 콜백 함수를 인자로 넘기는 패턴이다.
왜 사용하는가: 비동기 API는 return을 할 수 없는데, 함수의 실행이 끝나기 전에 제어권이 넘어가기 때문이다. 이를 해결하기 위해선 결과를 다른 함수에 넘기면 된다.
장점: 간단하고 효과적이다.
단점: 호출 깊이가 깊어지면 가독성이 감소된다. Callback Hell이라고 불린다.
2. Node.js에서의 CPS 패턴
Node.js는 CPS 패턴을 사용할 때 일관된 규칙을 따라야 한다.
argument 순서에 관한 규칙: (...params, callback) 과 같이, callback 함수를 마지막 인자로 넘겨야 한다.
callback 함수의 argument에 관한 규칙: (err, ...args) 와 같이, err가 첫 인자여야 한다.
err 인자의 경우, 항상 Error() 객체여야 한다. (이 부분은 잘 지켜지지 않는 듯 하다.)
3. CPS 패턴의 콜 스택
Node.js에서 비동기 API를 호출하는 경우, callback 함수는 프로그래머가 예상한 호출 순서로 구성된 스택을 갖지 않는다. 비동기 API가 완료됐을 때, 이벤트 루프에 의해 단일 함수로 Queue에 쌓인 후 다른 타이밍에 실행되기 때문에 새로운 스택에서 실행된다. 비동기 함수에서 예외를 던지면, Error를 반환하며 프로세스가 종료된다.
const fs = require('fs'); const readJsonThrows = (filename, cb) => { try { fs.readFile(filename, 'utf8', (err, data) => { if (err) return cb(err); cb(null, JSON.parse(data)); // cb이 없거나, data가 불량인 경우 exception 발생 가능. // 콜백 함수 내에서 try-catch하지 않는 경우 프로세스가 죽는다. }); } catch (err) { // 여기서도 catch할 수 없음. 호출 스택은 fs.readFile에서 끝나고, // cb은 별개의 새 스택에서 실행되기 때문 } };
// 만약 JSON.parse에서 오류나는 경우, 프로세스가 종료된다. readJsonThrows('C./test.json', (f) => f); /* SyntaxError: Unexcepted end of JSON input at JSON.parse at FSReqCallback.readFileAfterClose (internal/...) */
4. Node.js에서 비동기를 처리할 때 절대 하지 말아야 할 점들
1. 결괏값을 동기, 비동기 2가지 방식으로 전달하지 않는다.
결괏값이 비동기일것을 기대하고 이벤트 리스너를 등록할 때, 동기로 결괏값이 제공되는 경우 이벤트 리스너가 동작하지 않는다.
동기 반환값을 비동기화 한다. setTimeout, setImmediate, nextTick, Promise 등이 가능하다.
주의! 해당 글의 내용은 부정확한 내용이 아주 많을 수 있습니다. 책의 설명이 추상적이고 OS 개념이 많이 필요하므로 추후 정리가 완료되는 경우 따로 표시하겠습니다.
Node.js 철학 (Node Way)
최소 기능: 기능 개수를 최소한되므로, 개발자, 사용자 모두에게 간단함
Node.js 자체 뿐만 아니라 node 기반 모듈을 설계할 때도 동일하게 적용
KISS 원칙: 부족하더라도 복잡함보다 단순함이 더 낫다
Reactor 패턴과 Node.js 이벤트 루프
Reactor 패턴은 Node.js의 비동기 특성 - Node.js에서 여러 요청이 동시에 있는 경우는 항상 비동기 방식으로 작업을 처리한다 - 의 원인이자, 비동기 방식으로 작업을 처리하는 방법에 해당한다. Reactor 패턴을 배우기 전에, 동시성을 처리하는 2가지 방법에 대해서 알아보자.
Blocking I/O : 느린 I/O를 기다리는 방식
많은 스레드 개수: 소켓의 데이터를 매번 기다리게 되면 각 연결 별로 스레드가 적어도 하나씩 돌아야 한다. 기다리는 시간에 타 사용자가 기다리지 않게 하기 위해서이다.
비효율적인 대기 시간: I/O가 CPU에 비해 매우 느리기 때문에 블로킹 API는 스레드의 유휴 시간이 처리 시간에 비해 압도적으로 길 수 밖에 없다. 스레드가 아무 일을 하지 않은 상태로 긴 시간 존재한다.
스레드의 비용: 스레드는 그 비용이 싸지 않다. 아주 많은 스레드가 있는 경우, Context Switching만 해도 비용이 매우 클 것이고, 적은 스레드가 있는 경우 사용자를 처리하지 못하므로 비즈니스적으로 비용이 매우 클 것이다.
Non-blocking I/O: 비동기 API를 호출 시 바로 제어권을 반환(내부적으로 특정 상수를 반환)하여 CPU 유휴 시간을 최소화한다.
Polling: 비효율적으로 I/O를 처리하는 방식으로, 리소스는 데이터가 없을 때 읽기 조작을 요청 받는 경우 EAGAIN을 반환하는데, 이 때문에 값이 필요한 입장에선 리소스를 계속 확인해야 한다. 이걸 BUSY_WAITING이라고 하는데, CPU를 계속 활용하므로 효율적이지 못하다.
동기 이벤트 디멀티플렉서: 논블로킹을 처리하는 효율적인 방법으로, 이벤트가 완료될 때마다 큐에 이벤트를 쌓아놓고 처리를 수행하는 객체. 이벤트가 없으면 Block 상태로 대기한다.
이벤트 통지자가 감시 대상 리소스의 자원이 읽기가 가능할 때(즉, 이벤트가 완료되었을 때) Demultiplexer에게 통지한다. (이벤트 통지자 역할로 IOCP, epoll/kqueue 등이 있는 것 같다.)
Event가 발생하면 Event Demultiplexer가 깨어나 Queue에서 이벤트를 읽어들여 처리하면 됨. 이 시점에서 리소스의 I/O 작업은 (1)에서 이미 완료되어있으므로 동기식으로 처리하면 됨. 또한 처리 방식이 싱글 스레드이므로 공유 자원 문제도 존재하지 않는다.
리액터 패턴: 이벤트 디멀티플렉서 + 이벤트 루프 + 이벤트 큐 + 실행 환경(V8, 싱글 스레드!)
이벤트 디멀티플렉서는 I/O 처리가 끝나면 (완료된) 이벤트를 이벤트 큐에 넣어줌
이벤트 루프는 실행 환경 상에서 스택이 비는 경우(즉 모든 동기 코드가 실행이 끝났을 때 - 노드 환경에서 동기 코드는 얼마 없어서 최초의 동기 코드는 금방 끝나기 마련.), 이벤트 큐에서 이벤트를 꺼내어 실행 환경에 이벤트 핸들러를 올리고, 인자로 이벤트를 넘겨 수행함.
만약 async 내에 async가 있다면 해당 이벤트는 또 이 과정을 거침.
이벤트 디멀티플렉서의 구현체
libuv: 크로스 플랫폼으로(가상머신 느낌으로 각 OS에 대응되는 이벤트 통지자를 활용) 비동기 작업을 처리함. 단, libuv는 이벤트 디멀티플렉서 역할만 하는 게 아니라 이벤트 루프도 구현함.
프로그램을 간결하고 실용적으로 작성할 수 있게 한다. 합성이 되므로 함수를 부담 없이 나눌 수 있게 되어 더 작고 의미있는 단위의 함수를 더 편하게 작성할 수 있다. 이렇게 합성된 함수는 가독성이 좋다. 아무래도 객체지향 패러다임을 강하게 지원하는 언어들에선 함수 합성이 쉽지 않다. 애초에 순수 함수를 작성하기도 쉽지 않다. public static으로 도배할 순 없기 때문이다.
합성함수의 결합법칙
함수 합성은 수학에서의 합성함수와 같이 결합법칙이 성립한다. compose(f, compose(g, h)) === compose(compose(f, g), h)가 성립한다. Javascript 상에서 생성되는 함수가 동일하다는 것이 아니라, 그 실행 결과가 언제나 같다는 뜻이다.
결합법칙이 무슨 소용일까
합성한 함수들을 재귀적으로 합성한 경우, 결합법칙을 적용하면 결과 예측과 리팩토링 시에 유용하다.
그 예로, 아래 세가지 loudLastUpper 함수는 동일하다. 더 작고 더 의미있는 함수로 정의할수록 재사용성과 가독성은 높아진다.
// 순수하지 않은 함수 // Impure 객체로 접근하도록 하여 사용자에게 주의를 준다. const Impure = { getJSON: curry((callback, url) => $.getJSON(url, callback), ), setHtml: curry((sel, html) => $(sel).html(html), ), };
이번 글은 쉽다(?). 순수함수에 대해 이론적으로 다루고, curry 함수를 소개한다. 다만 객체지향과의 비교, 테스트와 설계에 대한 내 생각을 공유하므로 지식이 없으면 어렵게 보일 수도 있다.
순수함수?
순수함수는 수학에서 정의하는 함수와 동일하다. 입력에 대한 출력이 항상 동일하고, 입력에 대한 출력이 항상 1가지이다. 이게 가능하기 위해선 DB, HTTP, 현재 시간 등에 의존하면 안 된다! 함수 외부의 것과 함수 내용이 전혀 연관이 없어야 한다.
부원인과 부작용
영어권에서 흔히 side-effects라고 얘기하는 부수효과나 부작용은 함수 밖의 코드의 상태에 영향을 주는 일을 말한다. 부수효과를 크게 부작용과 부원인으로 구분할 수 있다. 부작용은 숨겨진 출력이고, 부원인은 숨겨진 입력이라고 생각하면 된다. 왜 외부의 상태와 상호작용하면 안 될까? 궁금하면 계속 읽어야 된다.
숨겨진 입력
숨겨진 입력이라고 하면 뭐가 있을까? Javascript와 같이 객체지향 패러다임을 지원하는 언어의 경우는 this가 항상 함수에 전달된다. this도 숨겨진 입력이다. 또한 함수 내부에서 new Date() 등의 코드로 현재 시간에 의존하는 경우도 숨겨진 입력이라고 할 수 있다. 둘 모두 외부의 상태를 변경하기 때문이다.
숨겨진 출력
숨겨진 출력은 함수를 실행했을 때 바뀌는 모든 것이라고 할 수 있다. 순수함수 내에서는 어떤 외부의 상태도 변할 수 없으므로, 어떤 외부의 상태가 조금이라도 변경된다면 그 함수는 순수하다고 할 수 없다.
부수효과는 복잡성 빙산
왜 외부의 상태와 상호작용하면 안 될까?
순수함수가 아닌 함수의 Signature는 프로그래머가 읽더라도, 심지어 객체지향 언어의 설계 방식대로 설계했더라도 무슨 부수효과가 일어날지 알 수 없다.
캡슐화는 좋은 규칙이지만 그 구현 코드를 읽기 전까지 부수 효과를 정확히 알 순 없다.
부수효과가 왜 복잡성 빙산일까? 프로그래머가 예상한 그대로 동작하지 않는 경우 논리적 버그의 원인이 되기 때문이다. 부수 효과는 해당 코드 혹은 해당 코드와 간접적으로 연관이 있는 코드를 수정했을 때 바뀌기 또한 쉽고, 바뀌었을 때 작동하지 않게 될 확률도 높다. 그래서 객체지향 방식으로 설계를 하는 경우 회귀테스트를 그렇게 많이 작성해야 하나 보다. 응집성과 캡슐화를 생각해서 상태 의존적이고, 변경 시 서로의 영향을 받아서 깨지기 쉽기 때문이다.
그래서 함수형 패러다임에서는 공유 자체를 하지 않는 방향으로 설계하도록 지향한다. 그 결과가 순수함수이다.
순수함수가 아니면 테스트하기 힘들다
어떤 함수가 부수효과가 있는 경우 이미 그 함수는 다른 코드랑 최소한 1번은 엮여 있을 수 밖에 없다. 덕분에 그 함수를 테스트하기 위해서는 다른 코드까지 테스트할 수 밖에 없고, 이 과정에서 Blackbox Testing이 불가능해진다. 구현 상세에 외부 코드와의 연관이 존재하기 때문이다. 이 과정은 객체지향 언어로 작성한 경우 자주 발생하며 덕분에 Mock을 자주 사용하게 된다. 또한 테스트 자체도 구현 상세의 변경에 취약하게 된다.
부수효과를 제거하기, 제거했을 때의 장점
부수효과를 제거하려면 순수함수를 만들고 사용하면 된다.
모든 부작용, 부원인은 숨겨진것이기에 이를 Signature에 명시하면 된다. 이렇게 명시하는 것은 객체지향 언어에서는 응집성과 캡슐화를 위해 구현 상세로 분류하여 함수 안에 전부 집어넣는 등 지양하는 편이지만, 함수형 패러다임에서는 권장된다. 덕분에 덜 복잡해지고, 훨씬 테스트하기 쉬워지며, 추론이 훨씬 쉬워지기 때문이다.
부수효과를 완전히 제거할 수는 없다.
아무래도 웹 등 실세계의 애플리케이션은 함수 내의 수식을 한 번 계산하고 종료하는 게 목적이 아니라, 부수효과로 불리는 것들 대부분을 사용하여 목적을 달성할 수 밖에 없다. 함수형 패러다임은 이런 한계를 인정하고, 가능한 모든 곳에서 부수효과를 제거하고, 제거할 수 없을 땐 강력히 통제한다.
순수함수의 조합과 재사용성
순수함수는 그 자체의 명료함 덕분에 재사용성과 조합이 굉장히 쉽고, 많이 조합하더라도 쉽게 그 결과가 예측 가능하다. 특히 한 번에 풀 수 없는 크고 복잡한 문제를 쪼개서 작은 함수의 조합으로 해결할 수 있다. 앞서 만들어 놓은 산출물을 쉽게 조합하여 새로운 문제를 해결할 수 있게 되고, 생산성도 비약적으로 늘어난다.
순수함수에 대한 간단한 사실들
순수함수는 수학의 함수와 동일한 정의를 갖는다.
순수함수는 (input, output) 쌍이므로 객체로도 표현 가능하다. (key,value 쌍)
순수함수는 항상 캐시 가능하다.
순수함수는 필요한 건 다 전달받는다(dependency injection)
동시성 문제가 적거나 없다. 공유하는 메모리가 없기 때문이다.
curry 함수
2번째 글에서 currying을 이미 다루었다. 그 때의 currying은 프로그래머가 함수에 대해 직접 curry한 방식이고, 이번에는 어떤 함수에 대해 알아서 curry된 함수를 반환하는 함수를 소개한다.
curry 함수는 함수를 받아, 인자가 완전히 전달되지 않은 경우 남은 인자를 받을 함수를 반환한다. curry 함수의 구현은 function.length와 bind, apply를 사용하는 게 핵심이다.
1 2 3 4 5 6 7 8 9 10 11
functioncurry(f) { const len = f.length; returnfunction$curry() { if (arguments.length < len) { // 원래 함수의 매개변수의 갯수보다 $curry에 전달된 매개변수의 갯수가 작은 경우. return $curry.bind(null, ...arguments); // $curry에 계속 전달받은 매개변수들이 bind 된다. (arguments가 계속 쌓인다.) } else { return f.apply(null, arguments); // 실제 함수 호출. } }; }
1 2 3 4 5 6 7 8 9 10
// 예시 const add = (a, b, c) => a + b + c; const addC = curry(add); const add1 = addC(1); const add1and2 = add1(2); const add1and2and3 = add1and2(3); console.log(addC(1, 2)); // function $curry console.log(add1(2)); // function $curry console.log(add1and2and3); // 6 console.log(add1and2(3) === add1and2and3); // true